
 Yahoo Lifestyle
Yahoo Lifestyle Ai2's Molmo shows open source can meet, and beat, closed multimodal models
The common wisdom is that companies like Google, OpenAI, and Anthropic, with bottomless cash reserves and hundreds of top-tier researchers, are the only ones that can make a state-of-the-art foundation model. But as one among them famously noted, they "have no moat" — and Ai2 showed that today with the release of Molmo, a multimodal AI model that matches their best while also being small, free, and truly open source.
To be clear, Molmo (multimodal open language model) is a visual understanding engine, not a full-service chatbot like ChatGPT. It doesn't have an API, it's not ready for enterprise integration, and it doesn't search the web for you or for its own purposes. You can think of it as the part of those models that sees an image, understands it, and can describe or answer questions about it.
Molmo (coming in 72B, 7B, and 1B-parameter variants), like other multimodal models, is capable of identifying and answering questions about almost any everyday situation or object. How do you work this coffee maker? How many dogs in this picture have their tongues out? Which options on this menu are vegan? What are the variables in this diagram? It's the kind of visual understanding task we've seen demonstrated with varying levels of success and latency for years.
What's different is not necessarily Molmo's capabilities (which you can see in the demo below, or test here), but how it achieves them.
https://youtu.be/tsbVZ3rDA2w
Visual understanding is a broad domain, of course, spanning things like counting sheep in a field to guessing a person's emotional state to summarizing a menu. As such it's difficult to describe, let alone test quantitatively, but as Ai2 CEO Ali Farhadi explained at a demo event at the research organization's HQ in Seattle, you can at least show that two models are similar in their capabilities.
"One thing that we're showing today is that open is equal to closed," he said, "And small is now equal to big." (He clarified that he meant ==, meaning equivalency, not identity; a fine distinction some will appreciate.)
One near constant in AI development has been "bigger is better." More training data, more parameters in the resulting model, and more computing power to create and operate them. But at some point you quite literally can't make them any bigger: There isn't enough data to do so, or the compute costs and times get so high it becomes self-defeating. You simply have to make do with what you have, or even better, do more with less.
Farhadi explained that Molmo, though it performs on par with the likes of GPT-4o, Gemini 1.5 Pro, and Claude-3.5 Sonnet, weighs in at (according to best estimates) about a tenth their size. And it approaches their level of capability with a model that's a tenth of that.
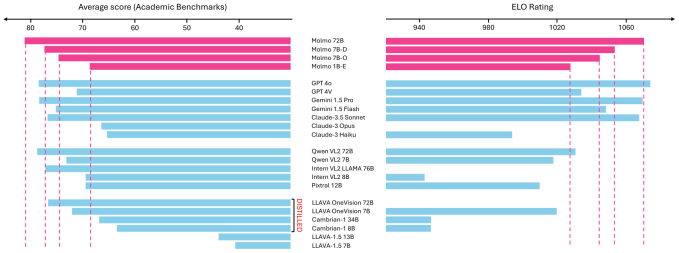
"There are a dozen different benchmarks that people evaluate on. I don't like this game, scientifically… but I had to show people a number," he explained. "Our biggest model is a small model, 72B, it's outperforming GPTs and Claudes and Geminis on those benchmarks. Again, take it with a grain of salt; does this mean that this is really better than them or not? I don't know. But at least to us, it means that this is playing the same game."
If you want to try to stump it, feel free to check out the public demo, which works on mobile too. (If you don't want to log in, you can refresh or scroll up and "edit" the original prompt to replace the image.)
The secret is using less, but better quality, data. Instead of training on a library of billions of images that can't possibly all be quality controlled, described, or deduplicated, Ai2 curated and annotated a set of just 600,000. Obviously that's still a lot, but compared with six billion it's a drop in the bucket -- a fraction of a percent. While this leaves off a bit of long tail stuff, their selection process and interesting annotation method gives them very high quality descriptions.
Interested in how? Well, they show people an image and tell them to describe it — out loud. Turns out people talk about stuff differently from how they write about it, and this produces not just accurate but also conversational and useful results. The resulting image descriptions Molmo produces are rich and practical.
That is best demonstrated by its new, and for at least a few days unique, ability to "point" at the relevant parts of the images. When asked to count the dogs in a photo (33), it put a dot on each of their faces. When asked to count the tongues, it put a dot on each tongue. This specificity lets it do all kinds of new zero-shot actions. And importantly, it works on web interfaces as well: Without looking at the website's code, the model understands how to navigate a page, submit a form, and so on. (Rabbit recently showed off something similar for its r1, for release next week.)
So why does all this matter? Models come out practically every day. Google just announced some. OpenAI has a demo day coming up. Perplexity is constantly teasing something or another. Meta is hyping up Llama version whatever.
Well, Molmo is completely free and open source, as well as being small enough that it can run locally. No API, no subscription, no water-cooled GPU cluster needed. The intent of creating and releasing the model is to empower developers and creators to make AI-powered apps, services, and experiences without needing to seek permission from (and pay) one of the world's largest tech companies.
"We're targeting, researchers, developers, app developers, people who don't know how to deal with these [large] models. A key principle in targeting such a wide range of audience is the key principle that we've been pushing for a while, which is: make it more accessible," Farhadi said. "We're releasing every single thing that we've done. This includes data, cleaning, annotations, training, code, checkpoints, evaluation. We're releasing everything about it that we have developed."
He added that he expects people to start building with this dataset and code immediately — including deep-pocketed rivals, who hoover up any "publicly available" data, meaning anything not nailed down. ("Whether they mention it or not is a whole different story," he added.)
The AI world moves fast, but increasingly the giant players are finding themselves in a race to the bottom, lowering prices to the bare minimum while raising hundreds of millions to cover the cost. If similar capabilities are available from free, open source options, can the value offered by those companies really be so astronomical? At the very least, Molmo shows that, though it's an open question whether the emperor has clothes, he definitely doesn't have a moat.

